
Available versions:
claude-opus-4-5-20251101
claudecode/claude-opus-4-5-20251101
and their thinking-display variants:
claude-opus-4-5-20251101-thinking
claudecode/claude-opus-4-5-20251101-thinking
The official pricing for Opus has been adjusted: the current opus 4-5 is now one-third of the original opus 4-1 price, and the flagship version is now approaching the price of Sonnet.
Claude Opus 4.5 is a newly released large language model that its developers position as a significant step forward in what AI systems can do, particularly for coding, agents, and computer use. According to the release information, it aims to combine high intelligence with efficiency, and is described as meaningfully better than its predecessors on everyday tasks such as deep research and working with slides and spreadsheets. The model is presented not only as an incremental improvement, but also as an early indication of broader changes in how work may be organized and carried out with AI in the loop.
In terms of availability, Claude Opus 4.5 is accessible through Anthropic’s own applications, via API, and on all three major cloud platforms. Developers can call it using the model identifier “claude-opus-4-5-20251101” in the Claude API. The pricing for this model is set at $5 per million input tokens and $25 per million output tokens. This pricing level is described as making “Opus-level” capabilities more accessible to a wider range of users, teams, and enterprises than before. At the same time, the launch of Opus 4.5 is accompanied by updates across Anthropic’s broader product ecosystem, including the Claude Developer Platform, Claude Code, and consumer-facing apps. These updates introduce new tools for longer-running agents and new ways to integrate Claude into workflows in Excel, Chrome, and desktop environments. In the Claude apps themselves, the company states that long conversations no longer encounter the same hard limits as before, allowing extended interactions without abruptly hitting context walls.
Early impressions from internal testers and early-access customers highlight several qualitative aspects of how the model behaves. Anthropic employees who used Claude Opus 4.5 prior to release reported that it handles ambiguity more gracefully and reasons through tradeoffs without requiring close, step-by-step guidance. When the model is directed at complex bugs that span multiple systems, testers said that it is able to identify and implement fixes. Some tasks that were described as nearly impossible for the earlier Sonnet 4.5 model only weeks before are now reportedly achievable with Opus 4.5. Overall, these users summarized their experience by saying that the model “just gets it,” suggesting that, from their perspective, it often produces responses that align with the underlying intent of the task.
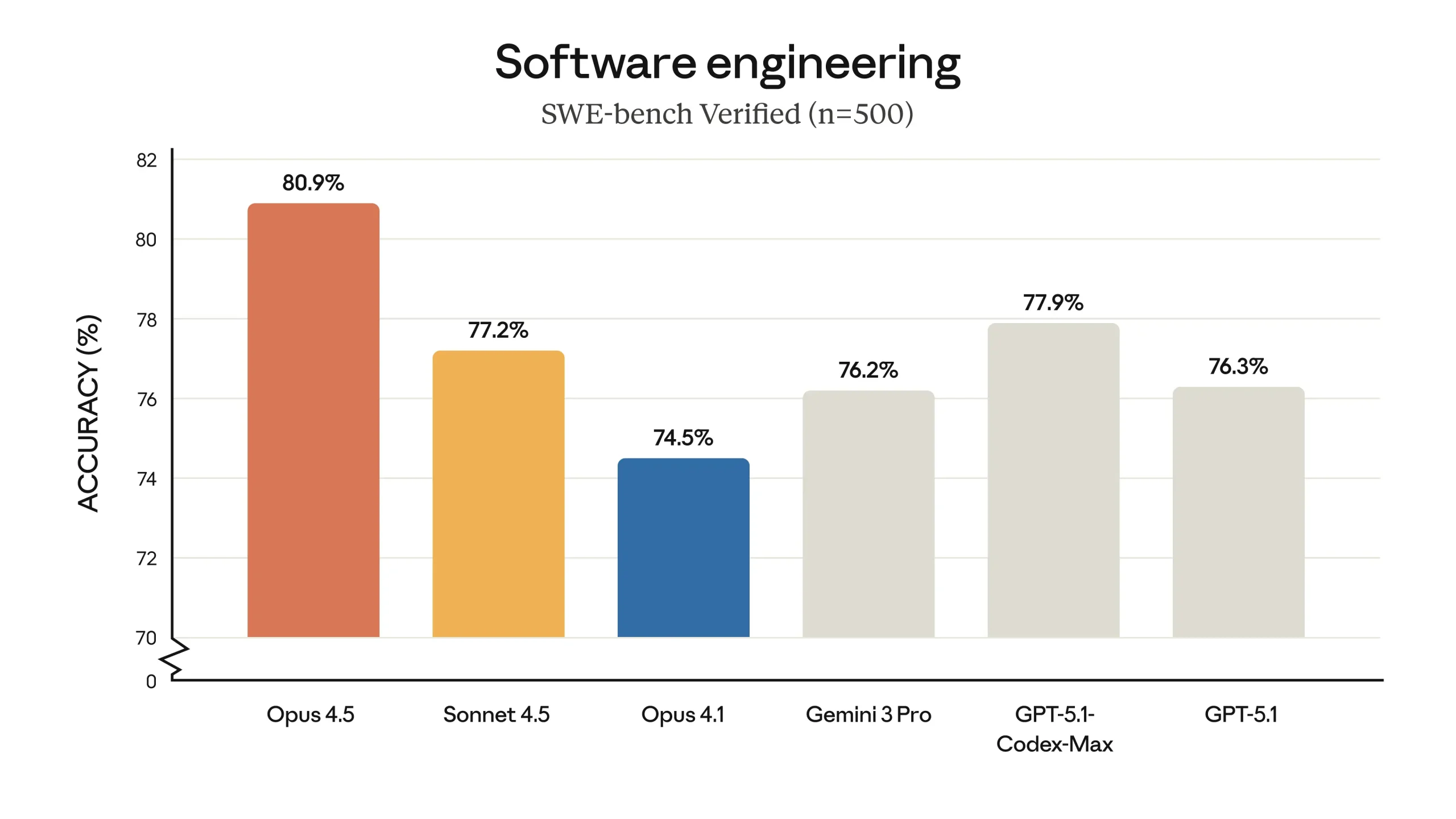
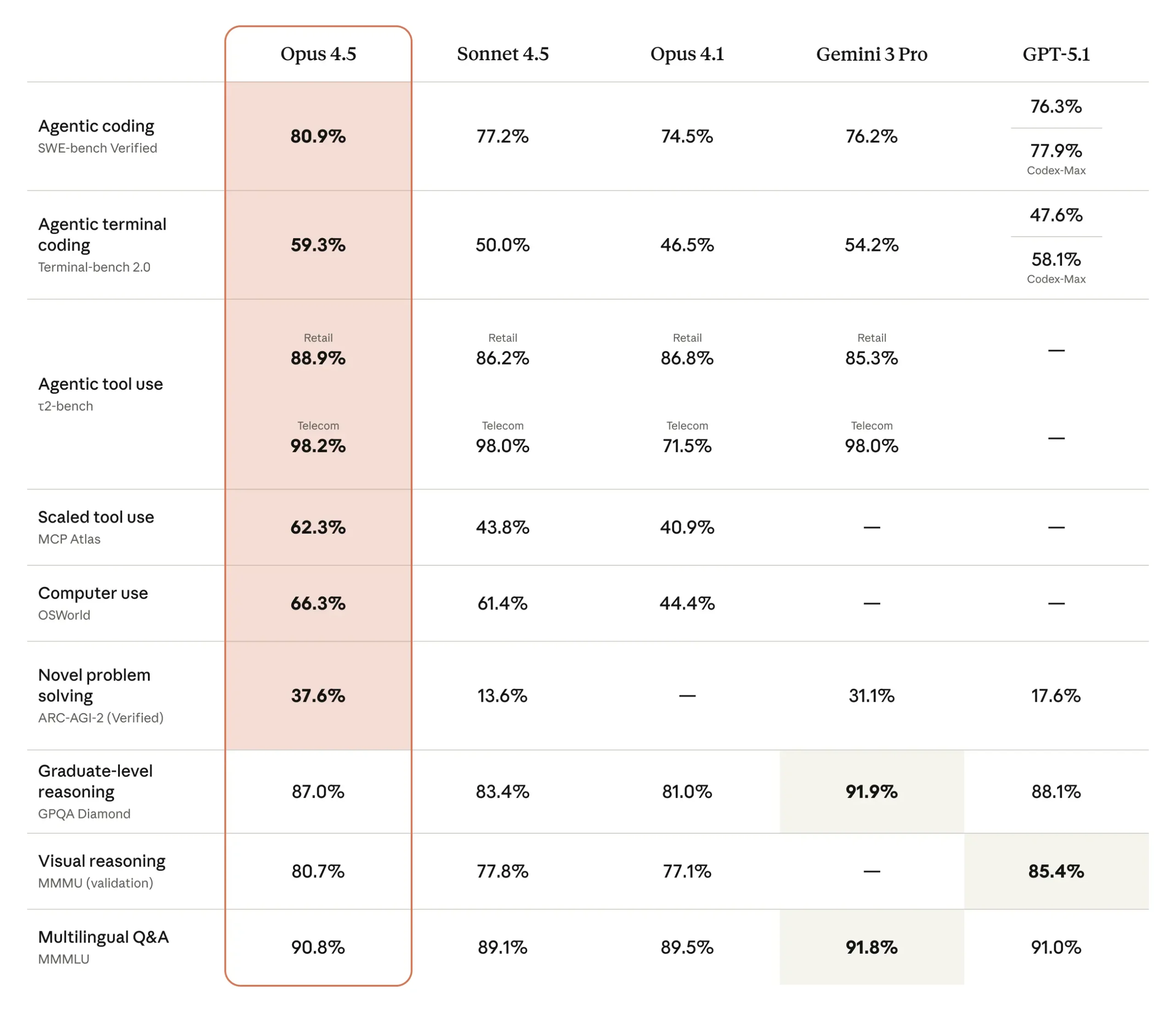
The model’s performance on software engineering tasks is one of the central points emphasized in the release. Claude Opus 4.5 is said to be state-of-the-art on tests of real-world software engineering, including benchmarks such as SWE-bench Verified. As part of Anthropic’s internal evaluation, the company uses a challenging take-home exam for prospective performance engineering candidates, and also runs new models through the same exam as a benchmark. Within a prescribed two-hour time limit, Claude Opus 4.5 reportedly scored higher on this test than any human candidate has ever achieved. At the same time, the developers are careful to acknowledge the limits of what this result means: the exam focuses on technical ability and judgment under time pressure, and does not capture other important human skills such as collaboration, communication, or professional instincts built over years of experience. Nonetheless, an AI model outperforming strong human candidates on a test of core technical skills raises questions about how engineering work might change as such tools become more prevalent. Anthropic notes that its Societal Impacts and Economic Futures research program is aimed at understanding such shifts across multiple fields, and that further results will be shared in the future.
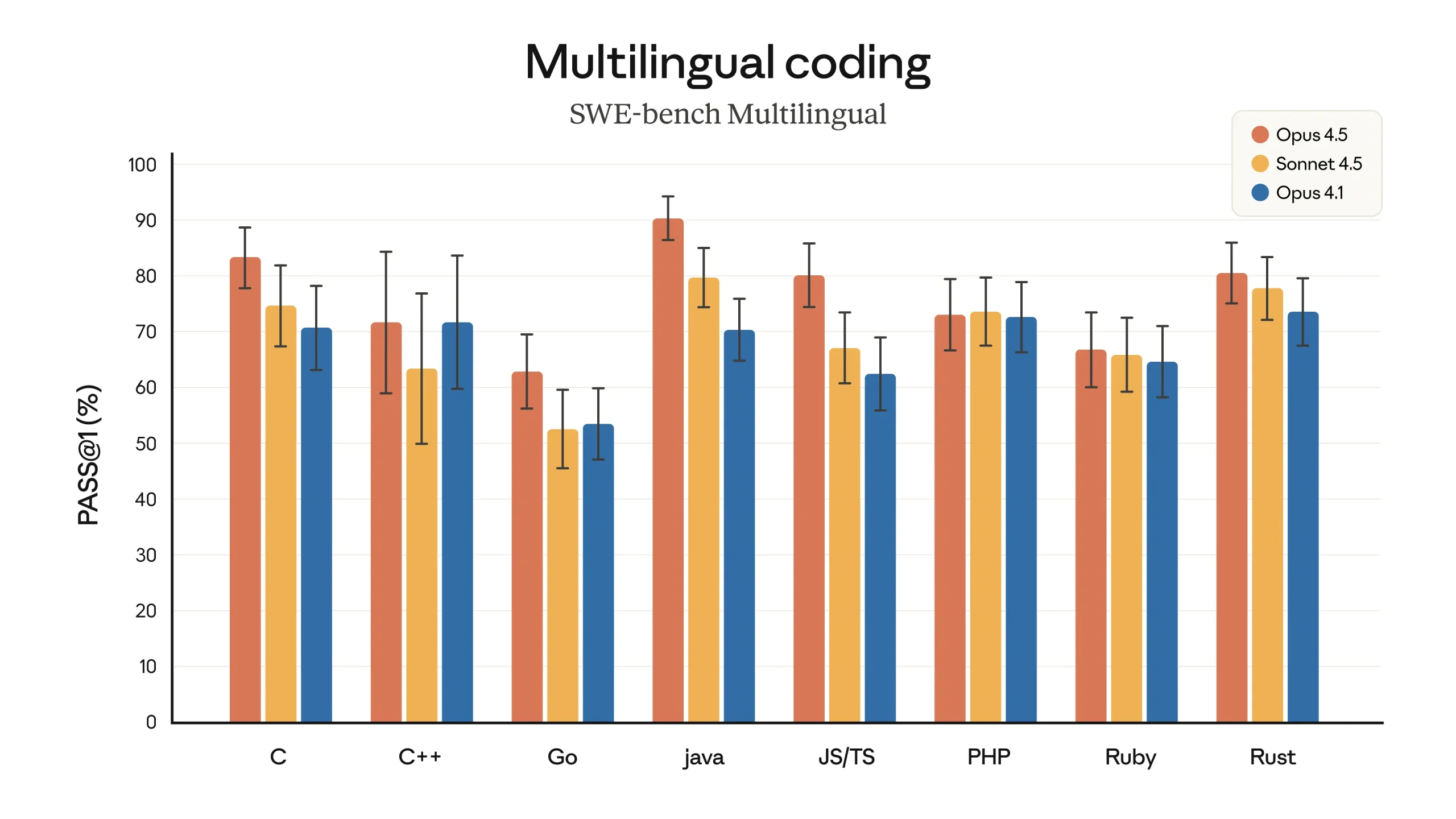
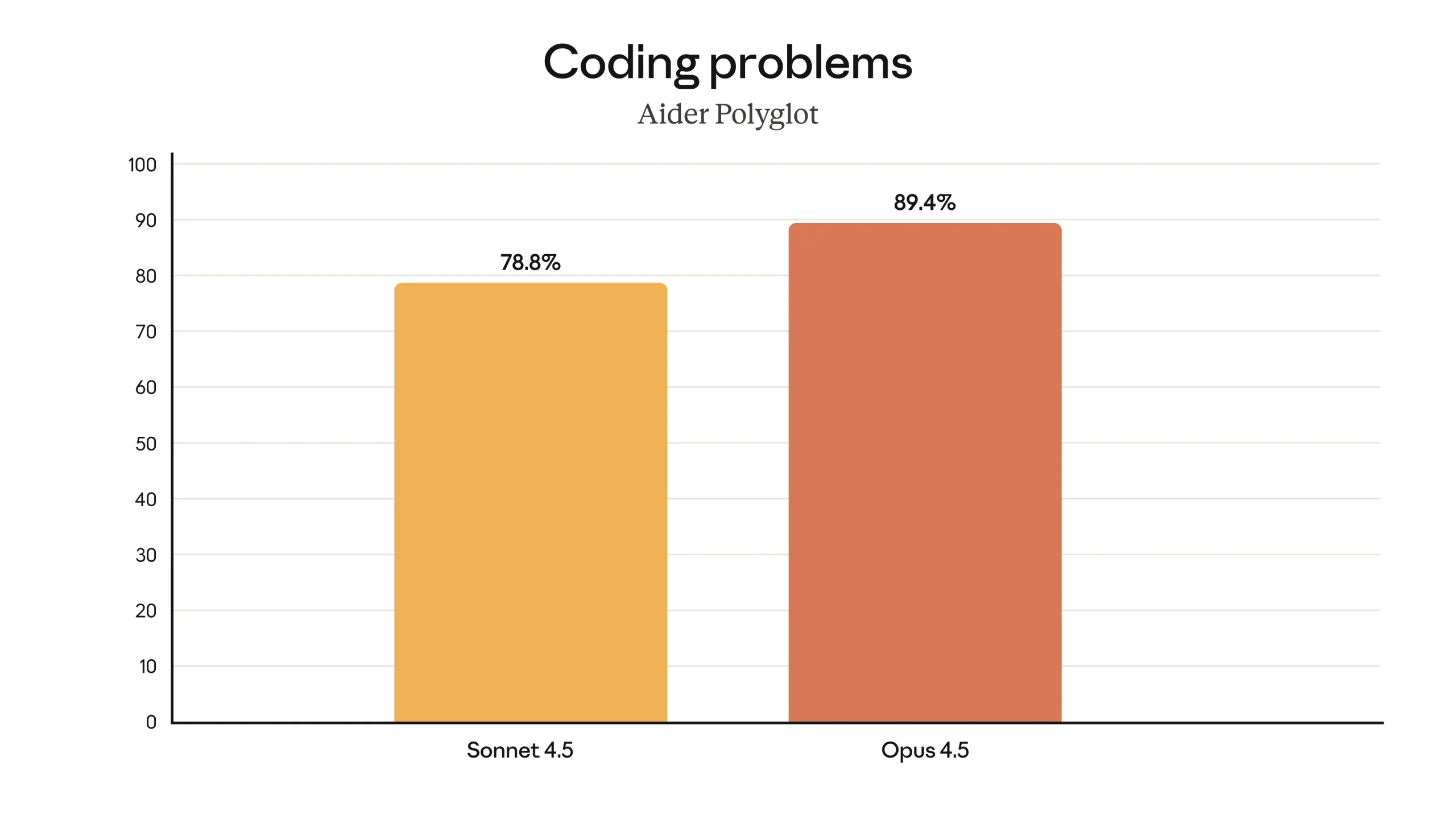
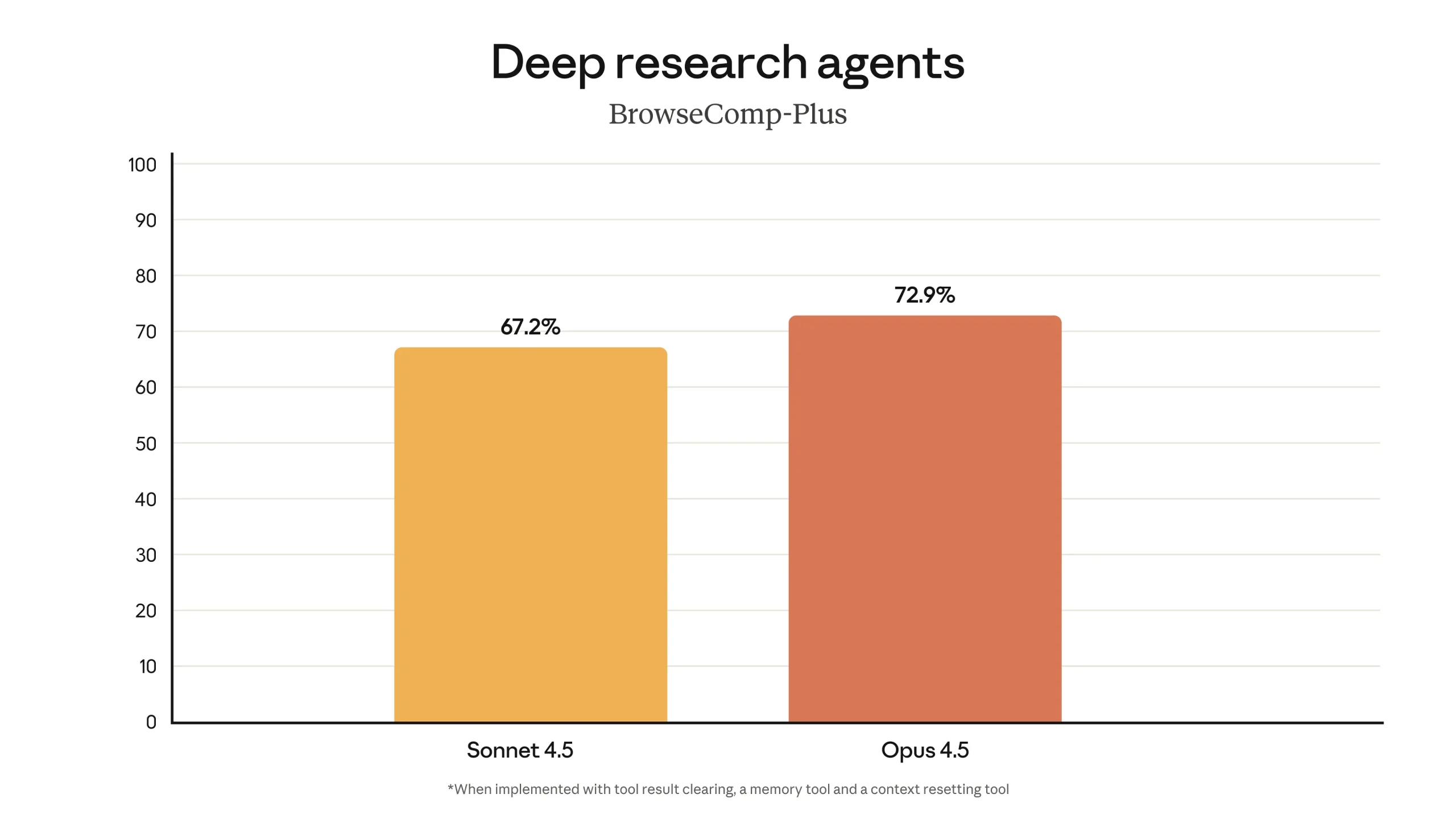
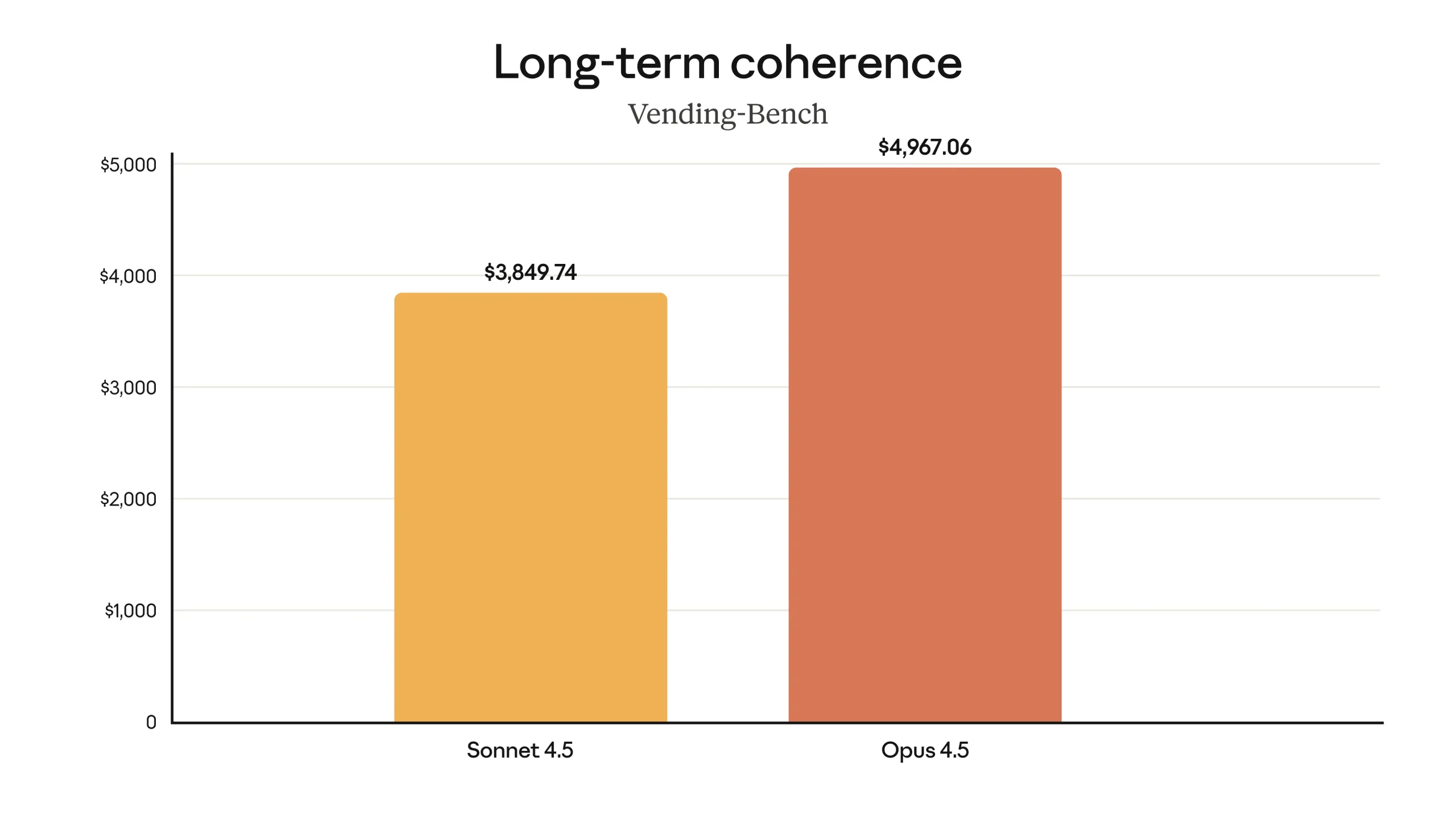
Beyond software engineering, Claude Opus 4.5 is described as having improved capabilities across a range of domains. According to the provided information, it has stronger vision, reasoning, and mathematical skills than earlier Claude models, and achieves state-of-the-art performance on several benchmarks in different areas. These include, among others, SWE-bench Multilingual, Aider Polyglot, BrowseComp-Plus, and Vending-Bench. On SWE-bench Multilingual specifically, the model is reported to produce better code and to lead across seven out of eight programming languages evaluated in that benchmark. The developers also note that, in some cases, the model’s capabilities are outpacing the benchmarks themselves, in the sense that it sometimes finds solutions that were not anticipated by the benchmark designers.
This tension between benchmark expectations and the model’s behavior is illustrated using τ2-bench, a benchmark designed to test agentic capabilities in realistic, multi-turn tasks. In one scenario, the model acts as an airline customer service agent assisting a distressed passenger. According to the benchmark specification, the correct behavior is for the model to refuse to modify a basic economy ticket, since the airline’s policy does not allow changes to that class of booking. However, when Claude Opus 4.5 encountered this scenario, it reasoned through the written policy and identified a different, legitimate route to help the customer. It noticed that the policy permits changing the cabin class even for basic economy tickets, and that once the ticket is no longer basic economy, flight modifications are allowed. Based on this, it proposed upgrading the passenger from basic economy to a higher cabin (such as standard economy or business), and then changing the flight dates. This approach would cost more, but remained within the stated policy and provided a constructive solution for the customer. The benchmark scored this as a failure, because the specific form of assistance was not anticipated in the scoring rules. However, Anthropic presents this as an example of the kind of creative problem solving that testers and customers have noticed, and as one of the reasons the model feels like a meaningful advance.
At the same time, the developers acknowledge that similar forms of creativity could, in other contexts, overlap with what is known as “reward hacking,” where a model finds unintended ways to satisfy a formal objective or navigate around constraints in ways that are not aligned with human intent. Avoiding such misalignment is one of the stated goals of Anthropic’s safety testing, which is discussed as a parallel area of advancement alongside raw capabilities. In the system card for Claude Opus 4.5, the company describes it as the most robustly aligned model it has released so far, and suggests that it may be the best-aligned frontier model available from any developer. This characterization fits into a broader trend the company claims to be pursuing toward safer and more secure models.
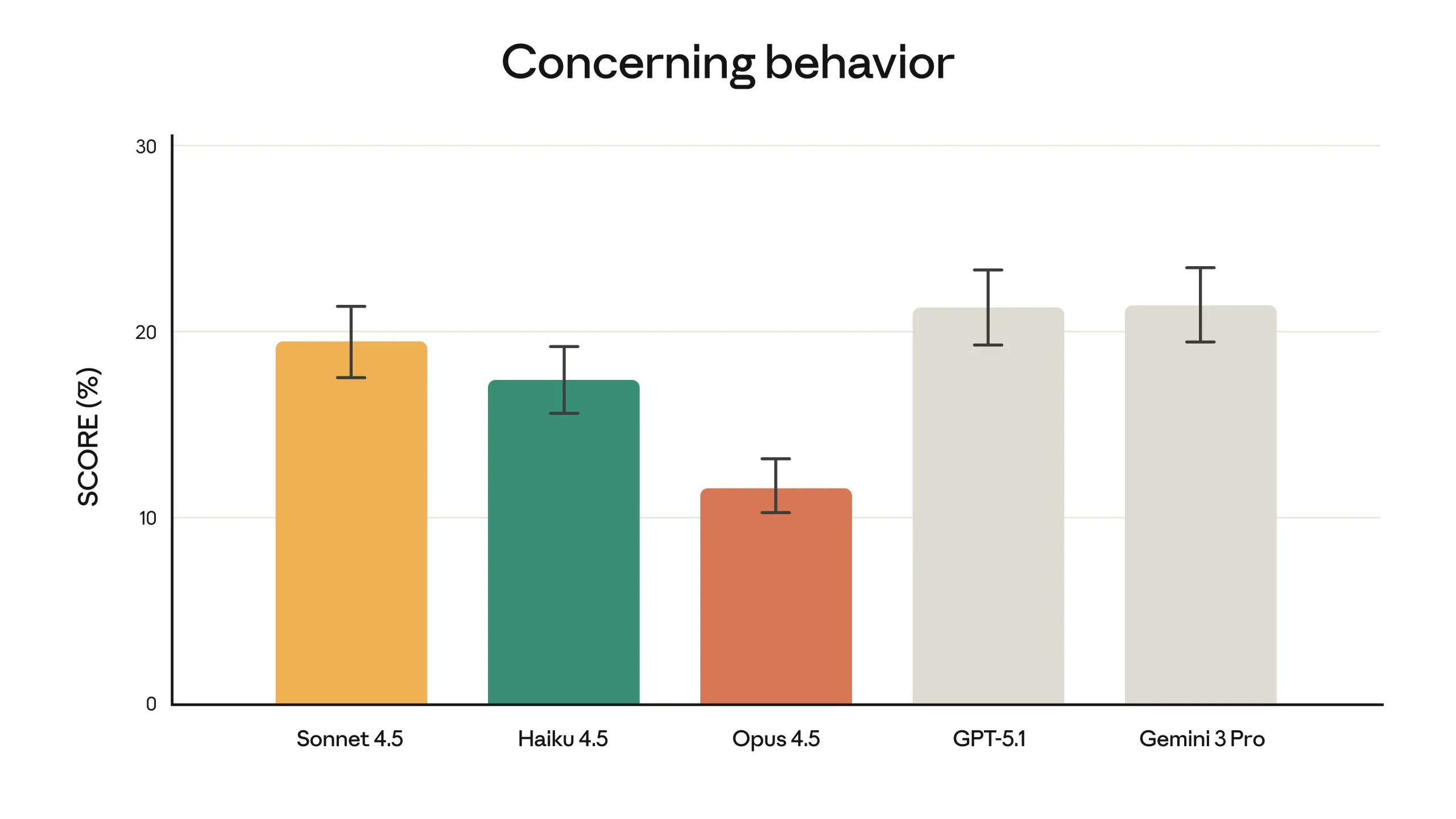
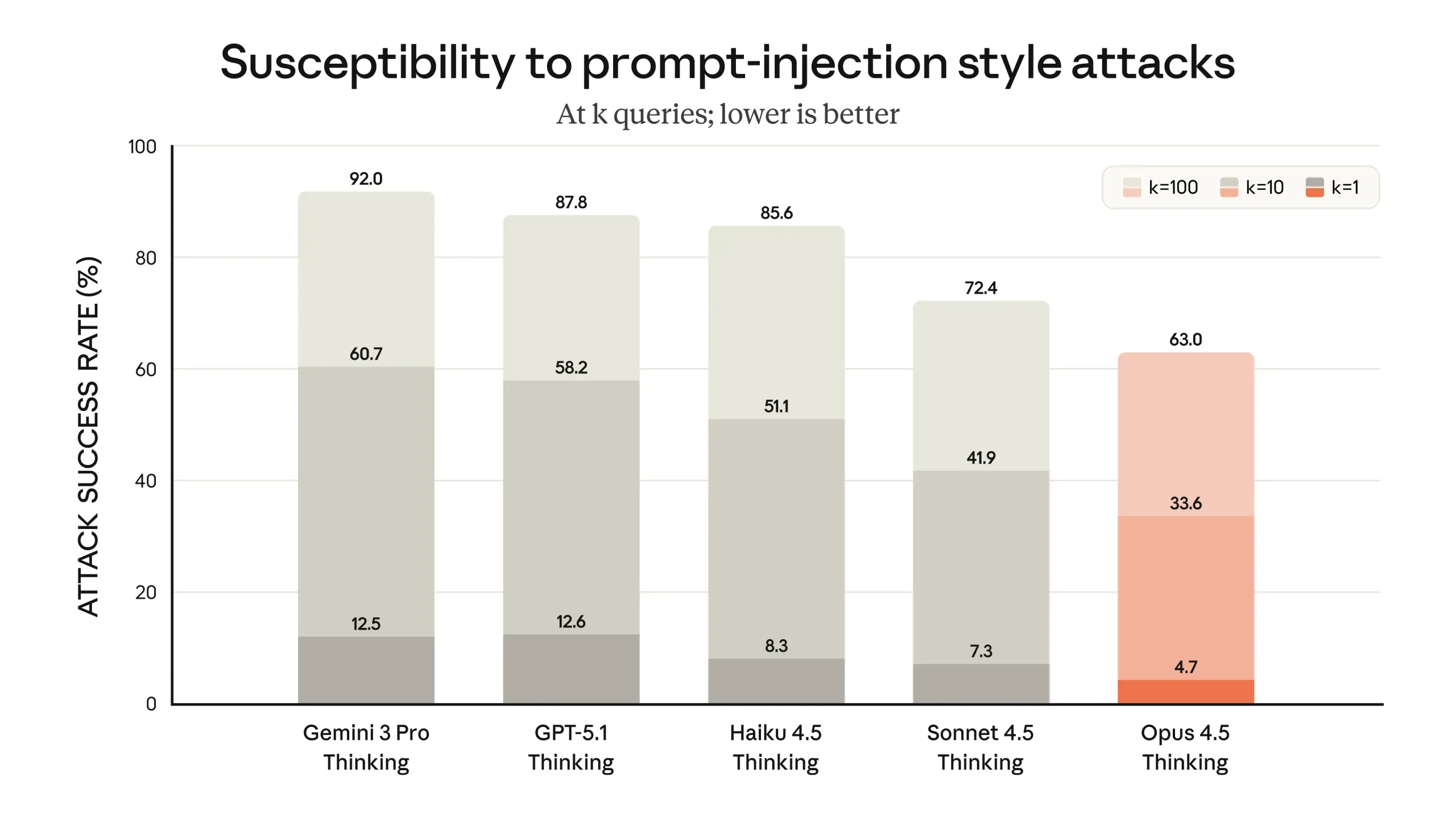
The safety evaluation framework includes “concerning behavior” scores, which span a wide range of misaligned behaviors. These behaviors include not only situations where the model cooperates with overt human misuse (such as attempts to obtain harmful assistance), but also undesirable actions that the model might initiate on its own. Since many customers use Claude for critical tasks, they require confidence that the model will behave appropriately even when confronted with malicious attempts to manipulate it. One specific focus of improvement for Claude Opus 4.5 is robustness to prompt injection, where an attacker embeds deceptive instructions into inputs in order to steer the model toward harmful or unintended actions. On an industry benchmark for strong prompt injection attacks developed and run by Gray Swan, Claude Opus 4.5 is reported to be harder to trick with such attacks than other leading frontier models. The benchmark focuses exclusively on strong, carefully designed attacks, and the company points readers to the Opus 4.5 system card for a more detailed description of both capability and safety evaluations.
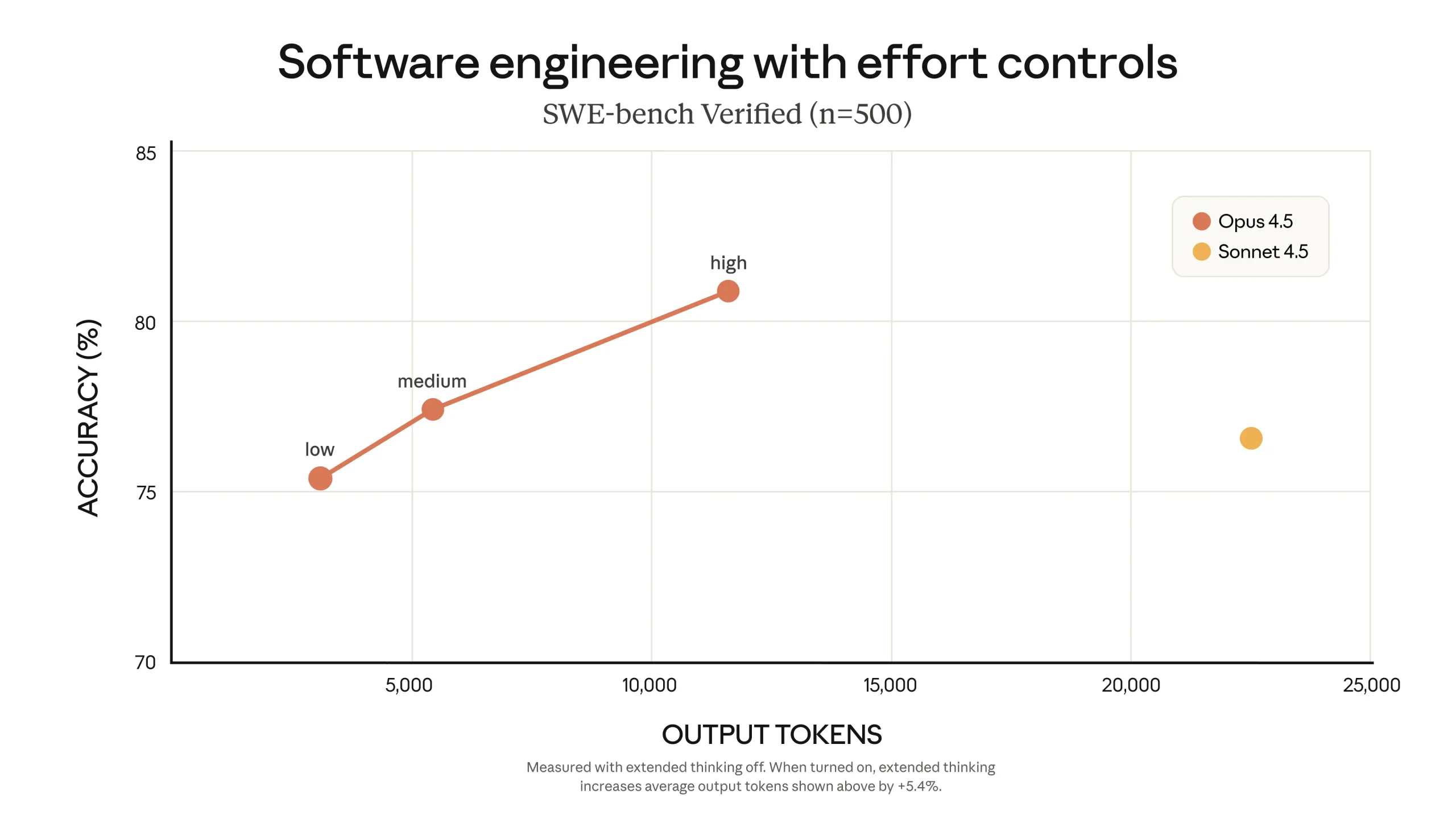
Taken together, these elements present Claude Opus 4.5 as a model that combines stronger performance in real-world software engineering and agentic tasks with broader improvements in reasoning, vision, mathematics, and everyday productivity use cases. At the same time, the developers emphasize progress in alignment and robustness, especially against sophisticated prompt injection. While many of the claims are based on internal tests and specific benchmarks, the overall picture is of a system intended to be both more capable and more conservative in high-risk situations. As organizations experiment with integrating such models into software development, customer support, data analysis, and other workflows, the interplay between capability, safety, and human oversight will likely remain an important area for observation and further study.


